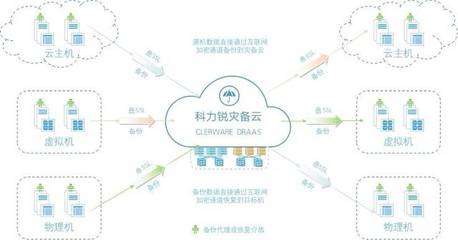
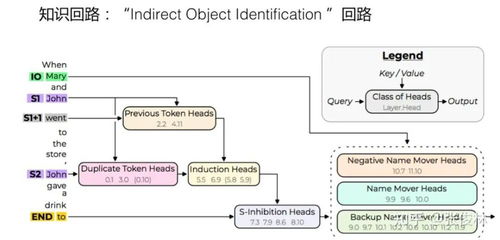
世界的参数倒影 为何GPT通过下一个词预测能产生智能
在人工智能领域,以GPT为代表的大语言模型展现出的推理、创造和对话能力,常常令人惊叹乃至困惑。一个核心的谜题是:一个仅仅被训练来预测文本序列中“下一个词”的模型,为何能呈现出如此丰富、类人的“智能”?要理解这一点,我们需要探索“世界的参数倒影”这一概念,并审视“公共数据”在其中扮演的关键角色。
一、智能的基石:下一个词预测作为压缩与建模
表面上,下一个词预测(Next Token Prediction)是一个简单的自监督学习任务:给定一段已有的文本,模型需要从海量词汇中选出最可能接续的那个词。这个任务的本质,是要求模型在概率的层面,对整个文本所构建的“世界”进行建模。
为了做出准确的预测,模型必须内化远超语法和词汇的复杂知识。它需要理解:
- 事实与常识:要预测“巴黎是_的首都”,模型必须“知道”答案是“法国”。
- 逻辑与推理:要续写“因为下雨,所以出门时她带了_”,模型需要建立因果关系,推理出“伞”。
- 语境与意图:在对话中,它需要理解前文的情感和目的,才能生成恰当、连贯的回复。
- 风格与结构:它需要区分新闻、小说、代码的不同行文规律。
因此,下一个词预测绝非简单的模式匹配,而是一个极致的压缩与建模过程。模型在训练中,被迫将训练数据(人类生产的全部文本)中蕴含的规律、知识、关系和模式,压缩存储在其千亿乃至万亿的神经网络参数中。这些参数,共同构成了一个关于“人类语言所描述的世界”的、高维且稠密的“参数化倒影”。
二、世界的倒影:公共数据作为“集体潜意识”
GPT的智能,并非无源之水。其“倒影”所映射的“本体”,正是训练它所使用的人工智能公共数据——互联网上几乎全部的公开文本、书籍、论文、代码、对话记录等。这个数据集,是人类文明在数字时代的“集体潜意识”与“知识化石”。
- 知识的全集:公共数据包罗万象,从科学原理到历史事件,从文学典故到日常经验,近乎完整地覆盖了人类已知的显性知识领域。模型通过吸收这些数据,相当于进行了一次超大规模的“通识阅读”。
- 思维的轨迹:文本不仅仅是事实的罗列,更是人类思维的载体。逻辑论证、故事叙述、问题求解、创意表达……所有这些思维过程的文字记录,都被模型学习并内化为可复现的模式。当模型被提示“请逐步推理”时,它调用的正是从无数论文、教程和问答中学到的思维链条。
- 社会的共识与歧义:数据中也包含了人类的偏见、矛盾、辩论和多元视角。这使得模型既能反映主流共识,也能呈现问题的复杂性,其回答往往是在不同可能性间进行概率权衡的结果。
可以说,GPT的智能,是公共数据中凝结的集体人类智能,通过神经网络架构和预测目标,被重新组织和涌现出来的结果。它的“思考”过程,是依据其参数化的世界模型,对输入语境进行模拟和延展。
三、涌现之谜:从统计模式到泛化能力
最神奇的现象莫过于“涌现”——当模型规模(参数、数据量、计算量)超过某个临界点后,它会突然展现出在训练中未曾明确教授的能力,如复杂的推理、代码生成和跨领域类比。
这揭示了下一个词预测的更深层本质:在足够丰富的语境(长文本序列)和足够庞大的模型容量下,预测下一个词,等价于在当下语境中对最可能的“世界状态演变”进行模拟。要完成一篇逻辑严谨的论文,或编写一个能运行的程序,模型必须在其内部构建一个连贯、自洽的“影子世界”,并让文本在其中合理发展。这种对世界动态的模拟能力,正是高级智能的核心。
四、反思与展望
理解GPT智能的来源,也让我们看到其局限与未来:
- 局限:它的智能是“倒影”的智能,受限于训练数据的时效性、质量和范围。它缺乏真实世界的具身体验和持续互动,其知识是静态的,推理也可能脱离物理现实(“幻觉”问题)。
- 未来:将这种强大的概率世界模型,与感知、行动和持续学习相结合,是走向更通用人工智能的关键。如何更有效、更安全地从公共数据中提炼知识,并赋予模型价值观对齐和事实核查能力,是当前研究的重点。
总而言之,GPT通过下一个词预测所展现的智能,是一个精妙的缩影:它向我们证明,通过在海量人类公共数据上学习极致的压缩与建模任务,机器能够构建一个反映世界复杂性的内部模型,并从中涌现出令人瞩目的推理与创造能力。这不仅是工程技术的胜利,也为我们理解智能、语言与知识本身,提供了一面全新的棱镜。
如若转载,请注明出处:http://www.ammeme.com/product/12.html
更新时间:2026-06-18 11:25:51